sequenceDiagram
participant Trainer
participant Model
participant Dataset
participant LossFunction
participant Optimizer
Note over Trainer: Initialization Phase
Trainer->>Model: Load model\nInitialize weights
Trainer->>Dataset: Prepare dataset
Note right of Dataset: Sequences of tokens (Numerical IDs) Labels (next token/class)
loop Until Converged
Note over Trainer: Mini-batch Sampling
Trainer->>Dataset: Sample random batch
Dataset->>Trainer: Batch inputs and labels
Note over Trainer: Forward Pass
Trainer->>Model: Predict with batch inputs
Model->>Trainer: Output logits
Note over Trainer: Loss Calculation
Trainer->>LossFunction: Compute loss (logits + labels)
LossFunction->>Trainer: Loss value
Note over Trainer: Backward Pass
Trainer->>Model: Backpropagate loss
Note right of Model: Compute gradients using chain rule
Note over Trainer: Weight Update
Trainer->>Optimizer: Update parameters (learning rate)
Optimizer->>Model: Adjust weights
end
Laith Zumot • 2025
The Cake 2016
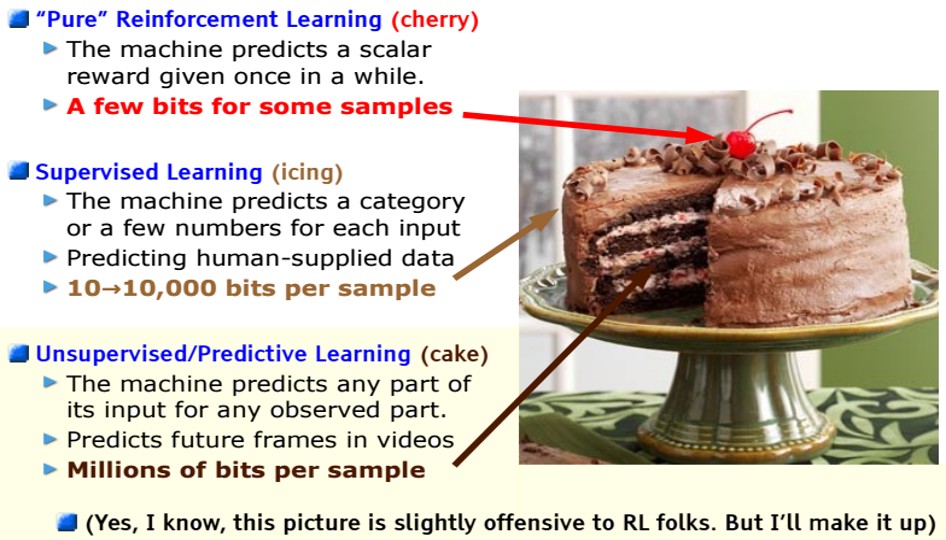
The Cake 2025

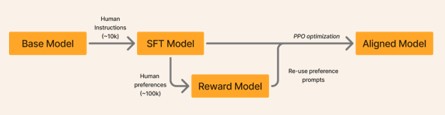
Pretraining
- Pre-train: Trillions of tokens
- Mid-train/Curriculum Train: Few Billion tokens

Post Training
- Supervised Finetune (SFT): 1mn’s samples
- Reinforcement Learning Post Training
- Preference/Alignment Finetune (RLAIF/RLHF) : 10k’s-1mn’s samples
- Reinforcement Learning with Verifiable Rewards (RLVR): 1000’s-100k’s samples
- Parameter Efficient Methods/Knowledge Distillation: 1000’s-1mn’s samples

Pretraining- Data & Architecture
Add knowledge for next token generation
- Data
- Scale matters
- Large-scale data != quality
- Constraints to access (80% scraped, <5% UGC)
- Curation: Parsing → Linearization → Cleaning → Filtering/PII → Deduplication
- Architecture
- SOTA keeps changing (GPT → Llama 3 → DeepSeek/Kimi/GPT-OSS)
- Scaling Laws no longer hold.

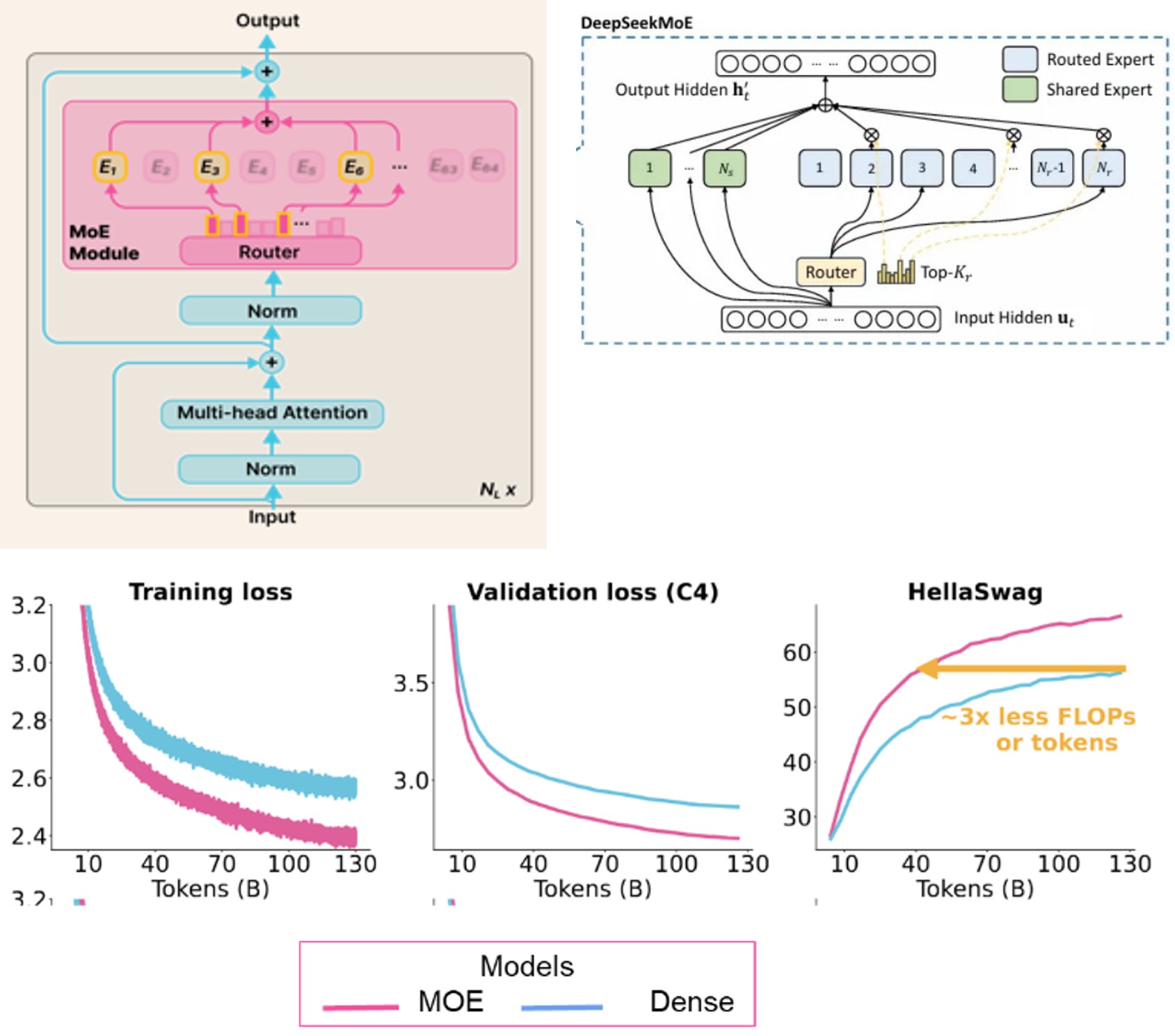
Mixtures of Experts
- A model with many “expert” sub-networks, but only few activated per input token
- (sparse activation), so effective capacity >> active compute.
- A learned gate picks the top-k experts for each token and mixes their outputs
- load-balancing losses keep traffic spread and avoid expert collapse.
- Can match (or beat) dense model accuracy with fewer tokens and lower total training FLOPs/MFUs.
- Requires expert-parallelism, high-bandwidth communication, capacity limits per expert, and careful routing to prevent hotspots.
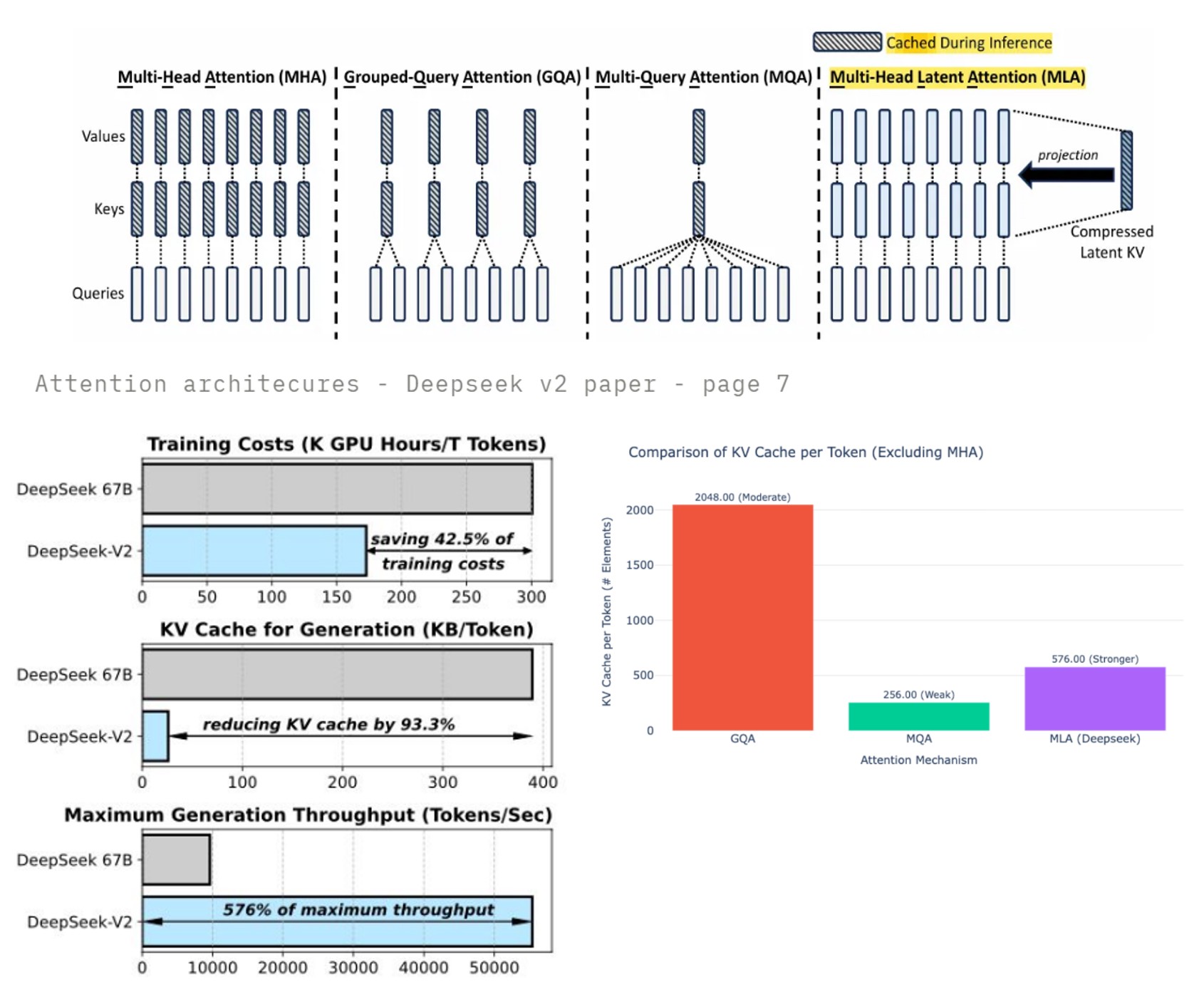
Multi-Head Latent Attention
- MHA originally used in GPT2/3
- Each head has its own K and V; Quality Vs. Memory. O(L · H · dₖ)
- GQA (Ainslie et al) popularized by Meta in Llama. ~ O(L · G · dₖ) w/ G ≤ H
- Multiple query heads share a smaller set of K/V heads (groups).
- Multi-Head Latent Attention introduced in DeepSeek-v2 paper
- Compresses keys/values into shared low-dimensional latent memory per token
- Uses lightweight per-head projections to read from that latent.
- O(L · d_latent) (typically much smaller)
- GQA/MLA add routing/projection machinery and custom kernels
Attention Sinks
- During decoding, every new token reads the entire cached K/V history. Big caches → lower batch sizes, shorter usable context, and GPU memory/bandwidth bottlenecks.
- Create one or more “always-attended” anchors so attention stays stable as sequences grow—crucial for streaming / sliding-window decoding.
- Keep the KV states of the first few tokens (or add a dedicated placeholder sink token) while using windowed attention; this lets LLMs trained on finite windows generalize to effectively infinite context with large speedups (reported up to 22.2× in streaming).
- Many LLMs naturally place large attention on the initial tokens (“attention sink” behavior). Preserving those tokens’ KV acts as a stable anchor that prevents degeneration when older context is dropped.
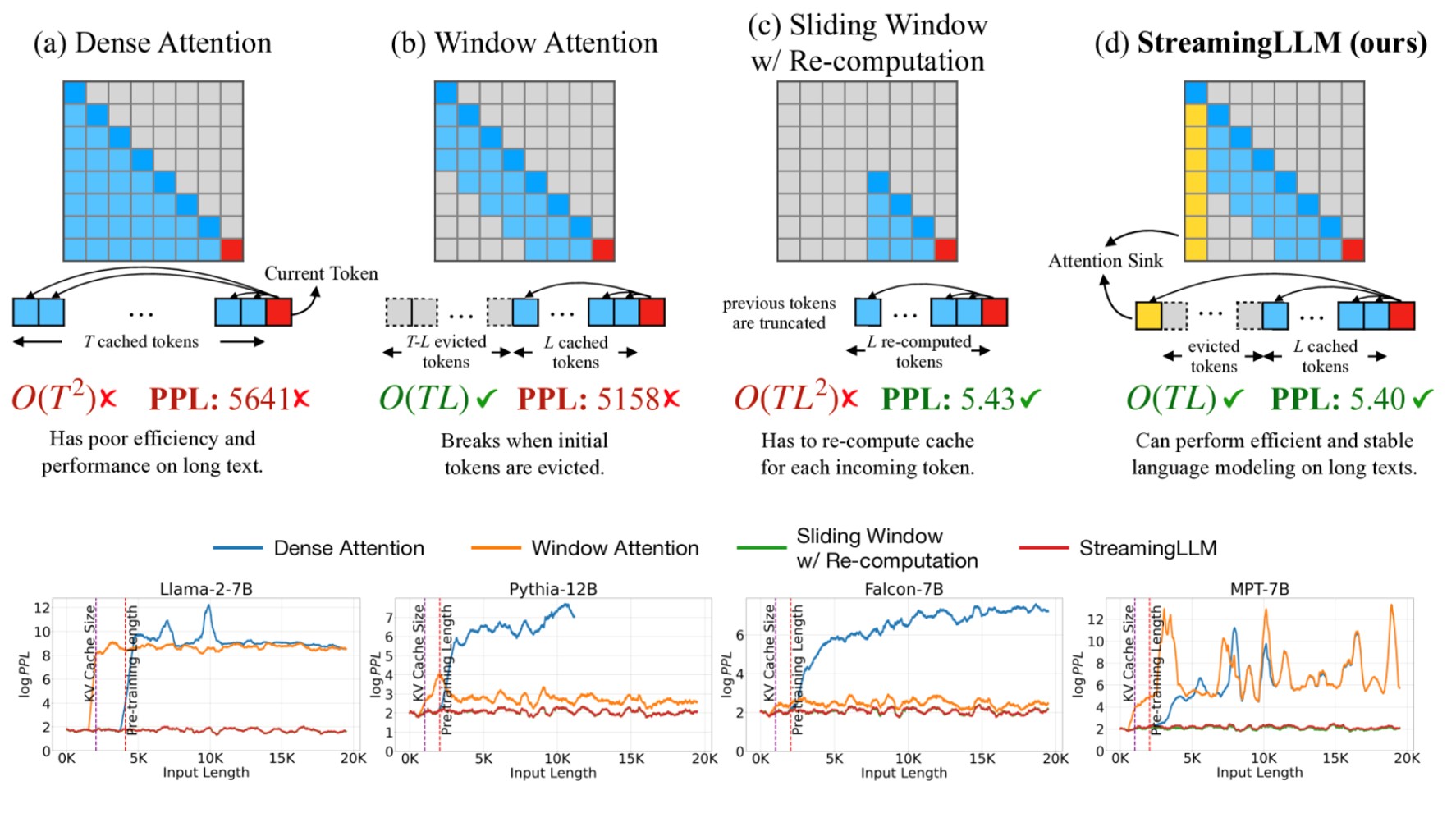
Attention Sinks
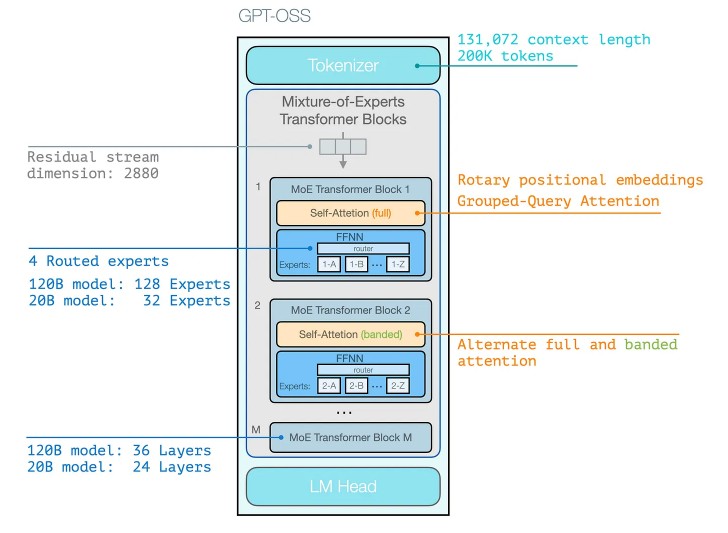
- GPT-OSS flavor (“sink attention”): Implements a per-head learned bias term inside the softmax (akin to adding a bias to the logits/normalizer) so each head can reserve or withhold attention—functionally serving as a global sink and enabling sliding-window patterns.
- MIT/StreamingLLM: explicit tokens whose KVs are always kept.
- GPT-OSS: learned per-head bias baked into the attention computation (no special tokens), paired with alternating dense + banded (sliding-window) layers.
- vLLM and NVIDIA NeMo ship kernels specifically optimized for GPT-OSS’s sink + sliding-window attention.
Post Training - Supervised Finetuning
- Adapt a pretrained LM for chat + tools using the right chat template, system prompts, tool/function tokens, stop/separator tokens, and safety prompts.
- Data curation/synthesis:
- Exploit eval gaps: For benchmarks where you’re weak, synthesize targeted data (prompt → reference answer / tool traces) to close those failure modes.
- Self-instruct / synthetic data: Seed with high-quality exemplars → generate instructions/solutions → filter (heuristics + model-grading + dedup + toxicity/harm filters).
- Human data for OOD: Use expert-written data for long-tail or safety-critical tasks (tools, multi-turn corrections, refusals).

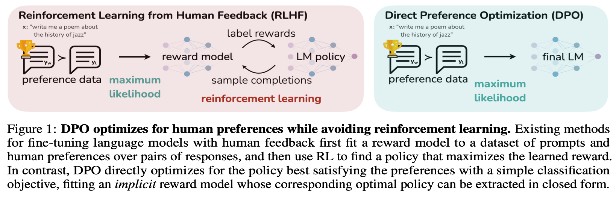
Post Training - Preference/RL Finetuning
- Helpfulness + harmlessness; stronger control over style and chat win-rates
- Target specific skills like long form chain of thought
- Approaches
- DPO / IPO / KTO (offline preference FT)
- Train directly on chosen vs. rejected pairs with a reference model for KL control.
- No reward model needed
- For style/harmlessness and stable training.
- RLAIF / RLHF (online RLFT)
- Use an AI or human judge (or a learned reward model) to score rollouts
- optimize with REINFORCE+/PPO/GRPO.
- Best when you need targeted capability shifts or safety trade-offs.
- DPO / IPO / KTO (offline preference FT)
Post Training - Preference/RL Finetuning
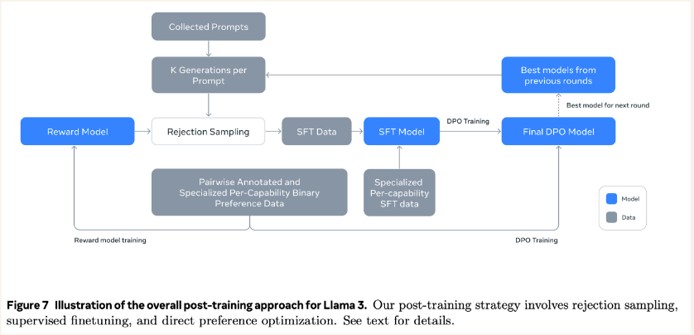
- text state → model action (next token) → full sequence → reward
- reward by human/AIF judge, RM, or verifiable test.
- Approaches
- Rejection sampling FT / Best-of-N:
- Sample, keep top responses by a judge/RM
- SFT on winners
- cheap, often strong.
- Verifiable rewards:
- Binary or programmatic checks (tools, math proofs, unit tests)
- for low-noise signals on specific skills.
- Rejection sampling FT / Best-of-N:
Post Training - Preference/RL Finetuning
- Data & rewards
- Sources: curated human comparisons (A/B), synthetic prefs (e.g., UltraFeedback-style), task-specific verifiable tests.
- Coverage: include safety prompts, tool-use JSON, refusal exemplars, long-form reasoning, multilingual if needed.
- Filtering: dedup, toxicity/policy screens, length-bias control (normalize rewards vs. tokens).
- Training recipe
- Low LR ~5e-7 (sometimes 1e-6 for smaller adapters); warmup 0–2%.
- Anchor to a reference (base/SFT checkpoint) to avoid drift/verbosity collapse.
- Pair-aware sample packing for DPO; for PPO, use short rollouts + frequent value/RM updates.
- Advantage normalization, entropy bonus, gradient clipping; monitor reward hacking vs. human prefs for stability
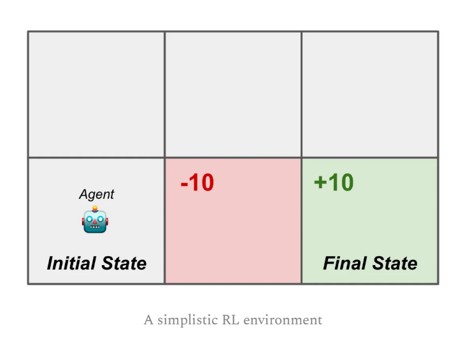
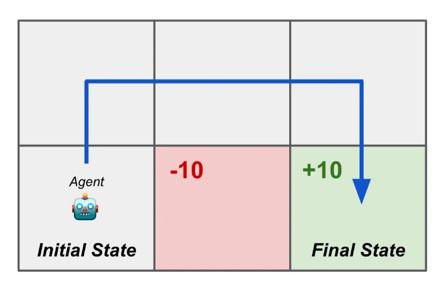
Post Training - Pref/RL Finetuning
- Evaluation
- Preference win-rate (Arena style), safety pass-rate, tool-call accuracy/JSON exactness, hallucination probes, length/latency.
- Keep a frozen validation judge; periodically sanity-check with human A/B to detect judge drift.
- Caveats & trade-offs
- Magnitude: smaller absolute gains than SFT; use precise targets and good judges.
- Data vs. compute: RLFT needs more training steps, often less data than SFT; DPO is data-hungry but compute-light.
- Generalization: SFT tends to memorize style; preference/RL yields better trade-offs (helpful/harmless/honest).
- Reward hacking: calibrate judges/RMs, add rule-based constraints, and audit for length bias.
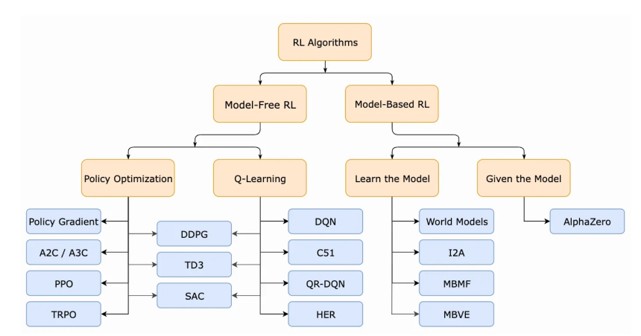
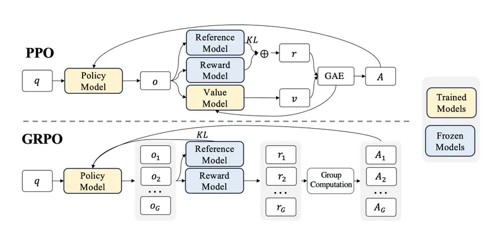
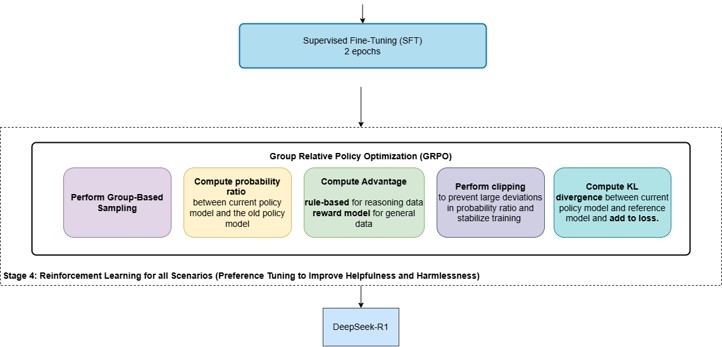
Post Training - Pref/RL Finetuning - GRPO
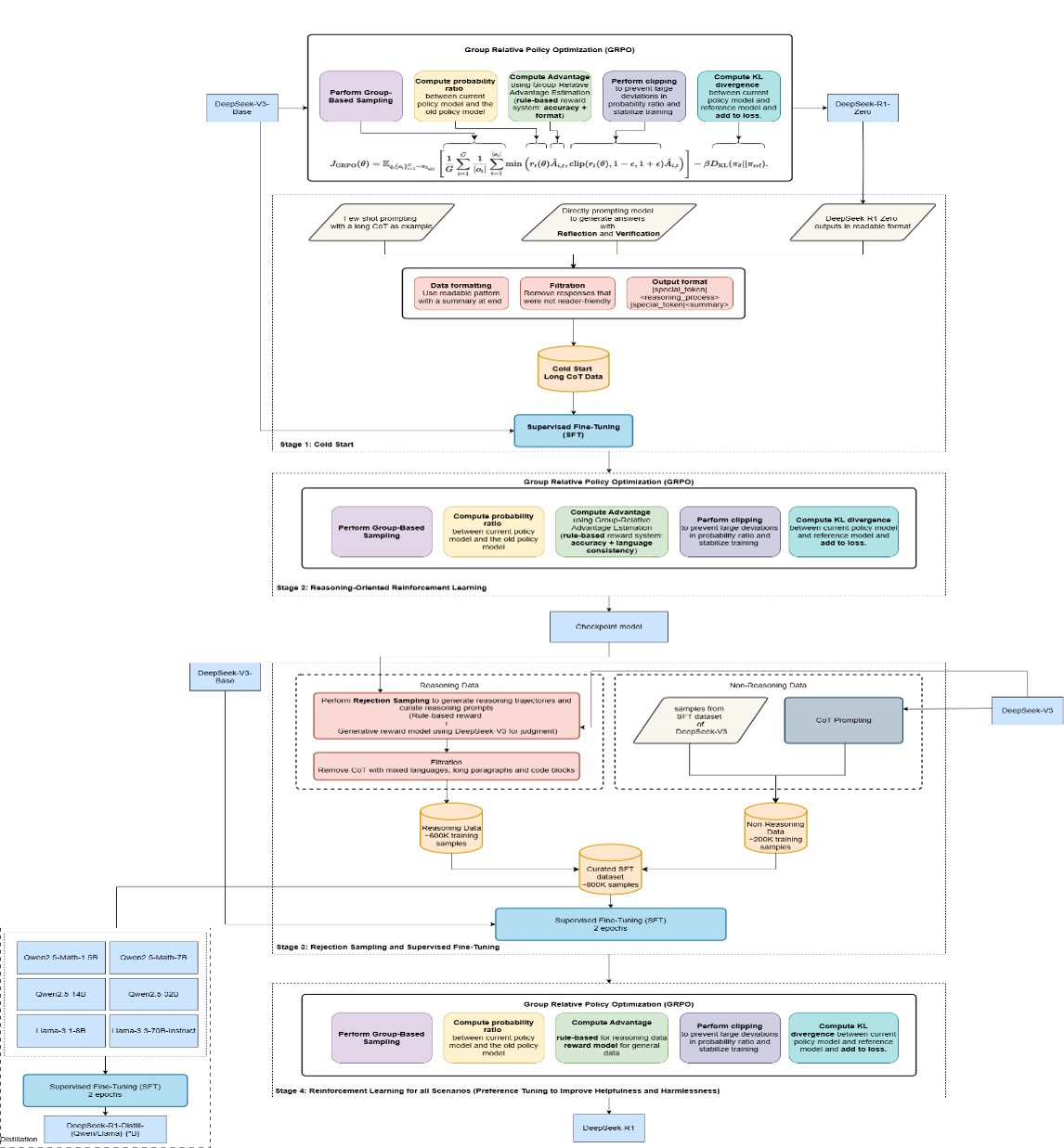
- Group Relative Policy Optimization (GRPO) — a critic-free, PPO-style RLFT method that learns from relative rewards across multiple samples per prompt.
- Maximize a PPO-like surrogate using the advantages plus a KL regularizer to a reference policy (per Shao et al., 2024).
- For each prompt, generate multiple outputs from the current policy (the “group”).
- Score each output with a reward model or rule-based/verifiable reward.
- Normalize → advantages:
- Standardize rewards within the group and use them as advantages, e.g. \(A_i = \frac{r_i - \mu_{\text{group}}}{\sigma_{\text{group}} + \epsilon}\)
LLM Training 3.0 - Deepseek V3/R1
- Stage -1: Pretrain Base-V3 on 15T tokens
- Stage 0: GRPO on Base-V3 to train R1-Zero (rewarded to reason and use a thinking format)
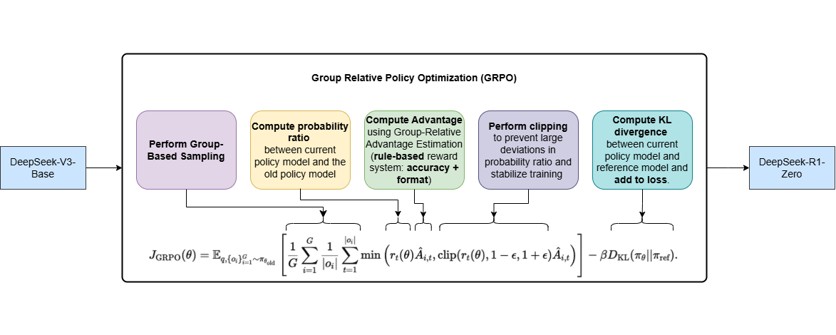
- Stage 1: Create “Cold-start” data for supervised finetuning Base-V3 again on synthetic reasoning data from the Stage 0 R1-Zero model (Curate CoTs to remove oddities).
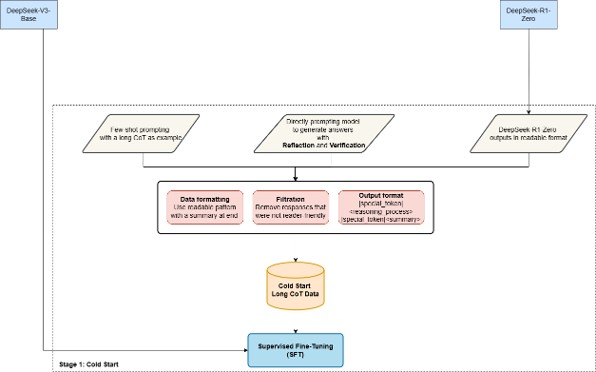
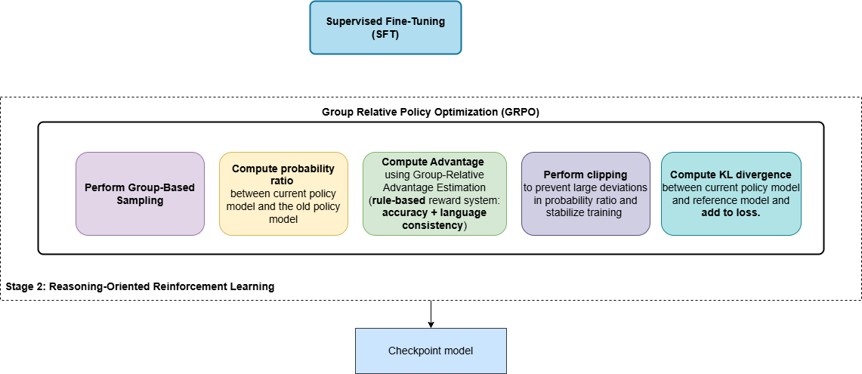
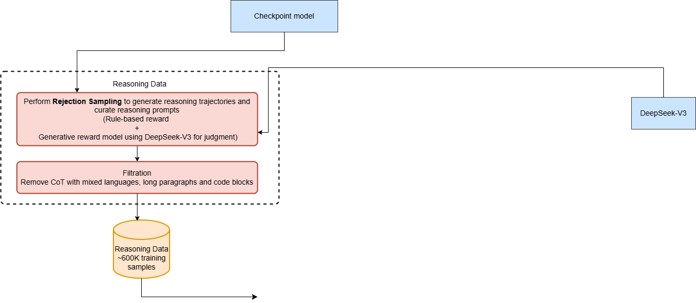
- Stage 2: Large-scale Reasoning Oriented reinforcement learning training on reasoning problems “until convergence” to produce Checkpoint model.
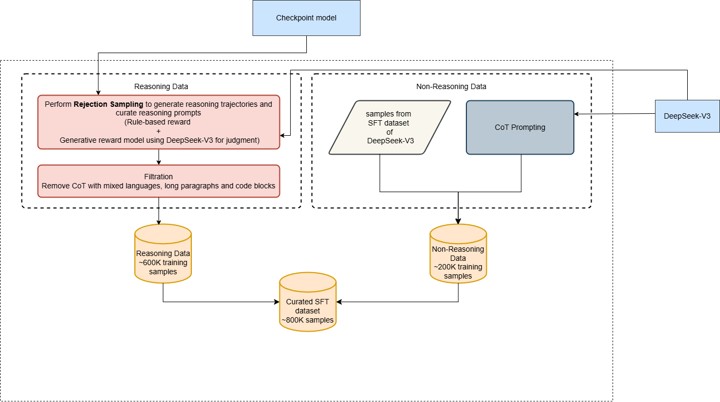
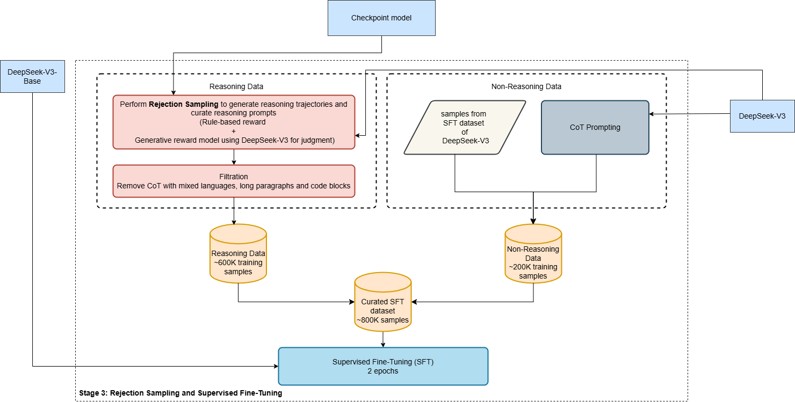
- Stage 3:
- Synthetic data using stage 2 model + pre-existing V3_Instruct to generate data for reasoning (600k+) and NON-Reasoning tasks (200k)
- Rejection sampling on reasoning problems using rules and V3-Instruct as judge to filter down to 600K samples
- Synthetic data using stage 2 model + pre-existing V3_Instruct to generate data as NON-Reasoning samples (200k)
- Combine 200+600 data
- SFT with these on Base-V3 again
- Stage 4: GRPO to preference tune for helpfulness/Safety and produce R1. (probably with some safety/toxicity/bias/style data)
- Distillation: Use Stage 3 800k data to distill smaller models
LLM Training 3.0 - Deepseek V3/R1
Stage 0 : R1-Zero - GRPO on Base-V3 to train R1-Zero (rewarded to reason and use a thinking format)
- Stage1 : Cold Start
- Create “Cold-start” data for supervised finetuning Base-V3 again on synthetic reasoning data from the Stage 0 R1-Zero model (Curate CoTs to remove oddities).
- Stage2 : Reasoning Oriented RL
- Large-scale Reasoning Oriented RL training on reasoning problems “until convergence”.
- Stage3a : Rejection sampling and SFT
- Rejection sampling on reasoning problems using rules and V3-Instruct as judge to filter down to 600K samples
- Stage3b : Rejection sampling and SFT
- Synthetic data using stage 2 model + pre-existing V3_Instruct to generate data as NON-Reasoning samples (200k)
- Stage3c : Rejection sampling and SFT
- SFT V3-Base with 800K samples
- Stage 4: R1
- GRPO to preference tune for helpfulness/Safety and produce R1.
Post Training - Distillation
Train a student model to match a teacher model’s output distribution (soft targets).
Loss (with temperature \(T\)): \[ \mathcal{L} = (1-\alpha)\,\mathrm{CE}(y, p_s) \;+\; \alpha\,T^2\,\mathrm{KL}\!\left(p_t^{(T)} \,\|\, p_s^{(T)}\right) \]
Backprop only through the student; the teacher is frozen.
Variants: use KL or JS divergence; mix in hard-label CE; schedule \(T\) or label smoothing.
Online distill: teacher forward + student forward/backward (higher GPU but no disk I/O).
Offline distill: cache teacher logits; cheaper GPU at train time but larger storage/I/O.
Issues:
- Training cost: Expect ~20–30%+ extra memory for activations/gradients beyond raw parameter memory (depends on context length, batch size, kernels).
- Exact logit matching can be restrictive; the student may imitate outputs without learning richer internals.
- Students may not learn intermediate representations; consider feature/attention distillation or auxiliary losses.
- length/verbosity bias from the teacher; mitigated with CE mixing, calibration, and data augmentation.

Training is half the battle
- Model Serving
- Evaluation
- Inference
- Guardrails
- Security
- Leakage
- UI/UX
- Knowledge Bases / Memory / Search
- Tool calling
- Agents
- LLMOps
- Lineage
- Infra
- AB testing
- Drift Management
