graph LR
A[Model Compression] --> B[Pruning]
A --> C[Distillation]
A --> D[Quantization]
A --> E[PEFT]
B --> B1[Unstructured Pruning]
B --> B2[Structured Pruning]
B --> B3[Rank Reduction]
C --> C1[Logit Distillation]
C --> C2[Hidden-State Distillation]
D --> D1[Post Training Quantization]
D --> D2[Quantization Aware Training]
Laith Zumot • 2025
Practical Model Compression

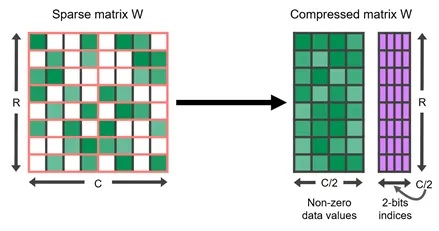
Quantization
- Reduce precision of weights/activations to shrink memory & speed up math
- e.g., BF16 → FP8.
- Lower memory footprint → larger batch / context on same hardware
- Higher arithmetic intensity → faster GEMMs / attention
- Cheaper deployment on edge/CPU
- PTQ (Post-Training Quantization)
- No retraining; quick to try
- Needs calibration data to estimate activation ranges
- Schemes: per-tensor/per-channel, symmetric/asymmetric
- Gotchas: outliers, distribution shift, layerwise sensitivity
- QAT (Quantization-Aware Training)
- Best accuracy under low bit-widths (fake-quant + STE)
- Matches deploy time numerics (quant/dequant in-graph)
- Common formats & typical use
- FP8 (e4m3/e5m2): high throughput training/inference; mild loss
- INT8: robust sweet spot for prod inference
- MXFP4: used in GPT-OSS for MOE experts (MP).

Distillation
Train a student model to match a teacher model’s output distribution (soft targets).
Loss (with temperature \(T\)): \[ \mathcal{L} = (1-\alpha)\,\mathrm{CE}(y, p_s) \;+\; \alpha\,T^2\,\mathrm{KL}\!\left(p_t^{(T)} \,\|\, p_s^{(T)}\right) \]
Backprop only through the student; the teacher is frozen.
Variants: use KL or JS divergence; mix in hard-label CE; schedule \(T\) or label smoothing.
Online distill: teacher forward + student forward/backward (higher GPU but no disk I/O).
Offline distill: cache teacher logits; cheaper GPU at train time but larger storage/I/O.
Issues:
- Training cost: Expect ~20–30%+ extra memory for activations/gradients beyond raw parameter memory (depends on context length, batch size, kernels).
- Exact logit matching can be restrictive; the student may imitate outputs without learning richer internals.
- Students may not learn intermediate representations; consider feature/attention distillation or auxiliary losses.
- length/verbosity bias from the teacher; mitigated with CE mixing, calibration, and data augmentation.
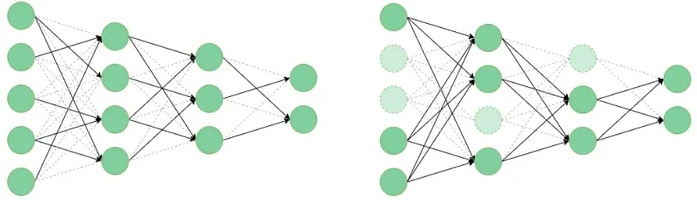
Pruning
Reduce params/FLOPs/VRAM; potential latency gains (esp. with sparse kernels).
How weights are pruned
- Unstructured (element-wise): highest sparsity; requires efficient sparse kernels
- Structured (channels/filters/heads): immediate speedups; lower flexibility
- N:M sparsity (e.g., 2:4): HW-friendly pattern; good accuracy/speed trade-off
Which weights to prune
- Magnitude-based (|w|, L1/L2): simple, strong baseline
- Movement pruning (|Δw| during fine-tune): preserves changing weights
- Gradient/Taylor saliency: |g·w| (first-order importance)
- SNIP/GRASP (pre-train sensitivity analysis);
- Optimal Brain Surgeon (2nd-order, costly)
- Head importance via contribution/entropy; prune low-value heads
- Magnitude-based (|w|, L1/L2): simple, strong baseline
Scheduling
- One-shot: prune once → (re)train (fast/risky)
- Iterative/gradual: increase sparsity over steps
- Example cubic schedule to target S*: S(t)=S*·(t/T)^3
Pruning — Strategies
- What counts as “prunable”?
- Global Rank weights across all layers → prune globally. Maximizes sparsity.
- Layerwise layer-specific thresholds to avoid over-pruning critical layers.
- How to fix accuracy post-pruning
- Retrain/Rewind: Fine-tune the pruned model; optionally revert to a pre-pruning checkpoint.
- Optionally add distillation style loss (logits or hidden states) to mimic the original model’s outputs/logits during retraining
- End-to-end workflow
- Establish baseline: task metrics, perplexity, latency/throughput, VRAM.
- Sensitivity sweep: per-layer sparsity curve (e.g., 0→90%) to find fragile blocks.
- Choose pattern: unstructured | structured (channels/heads) | N:M (e.g., 2:4).
- Set sparsity budget: global target + layerwise caps (protect embeddings/LN).
- Schedule: one-shot or gradual (e.g., cubic to S* over T steps).
- Prune & recover: brief fine-tune with small LR; consider distillation.
- Export & realize speed: use kernels that honor sparsity (structured / N:M).
- Validate in prod-like loads: seq length, batch size, mixed precision.
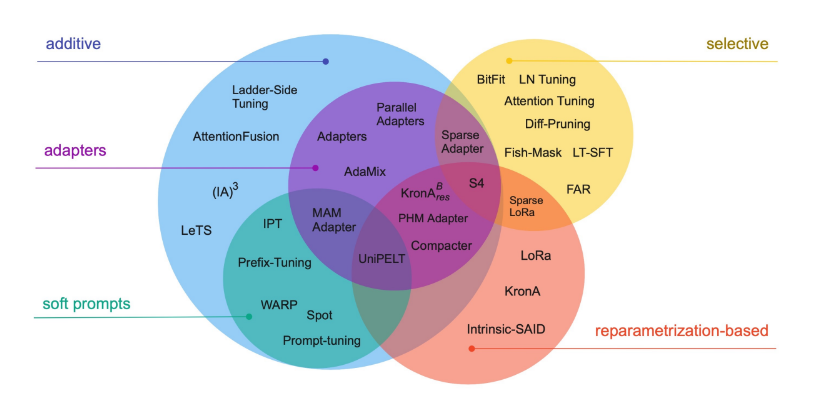
PEFT
- Parameter-Efficient Fine-Tuning = freeze the base model and train a small set of extra parameters (adapters, low-rank deltas, prompts).
- Tiny trainable footprint (often <1% of params) → fits on modest GPUs
- Faster training & lower memory/IO; checkpoints are small & swappable
- Multi-task: keep multiple adapter heads for different domains
- Core patterns
- Adapters: small bottleneck MLPs inserted in blocks
- LoRA/DoRA: learn low-rank (or decomposed) deltas on weight matrices
- Prefix/Prompt/Soft-prompt: learnable tokens prepended to inputs/keys
- IA³ / BitFit: learn per-feature scalars (attn/FFN) or just biases
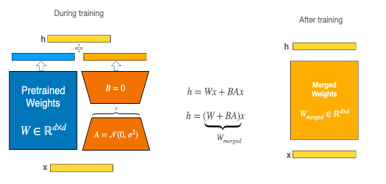
LoRA Deep Dive — mechanics
Freeze base model weights:
\[\begin{aligned} $W \in \mathbb{R}^{d_\text{out} \times d_\text{in}}$ \end{aligned}\]Learn low-rank weight delta:
\[\begin{aligned} W' &= W + \Delta W \\ \Delta W &= BA \\ \end{aligned}\] \[\begin{aligned} where: $A \in \mathbb{R}^{r \times d_\text{in}}$ , $B \in \mathbb{R}^{d_\text{out} \times r}$, $r \ll \min(d_\text{in}, d_\text{out})$ \end{aligned}\]Apply adaptive scaling:
Forward pass uses: \[Wx + \frac{\alpha}{r} B(Ax)\] (\(\alpha\) = tunable scaling constant)Optional regularization:
LoRA Dropout applied directly to input \(x\)